目录
一,Requests库练习
1,用百度 360 搜索关键字
2,图片爬取并保存本地
二,网络爬虫之信息提取——Beautiful soup库学习
1,安装Beautiful soup
2,运用Beautiful soup获取源代码
3, beautifulsoup使用格式
4,beautiful的基本使用元素
? beatiful soup库 决议器
beautiful soup类基本元素
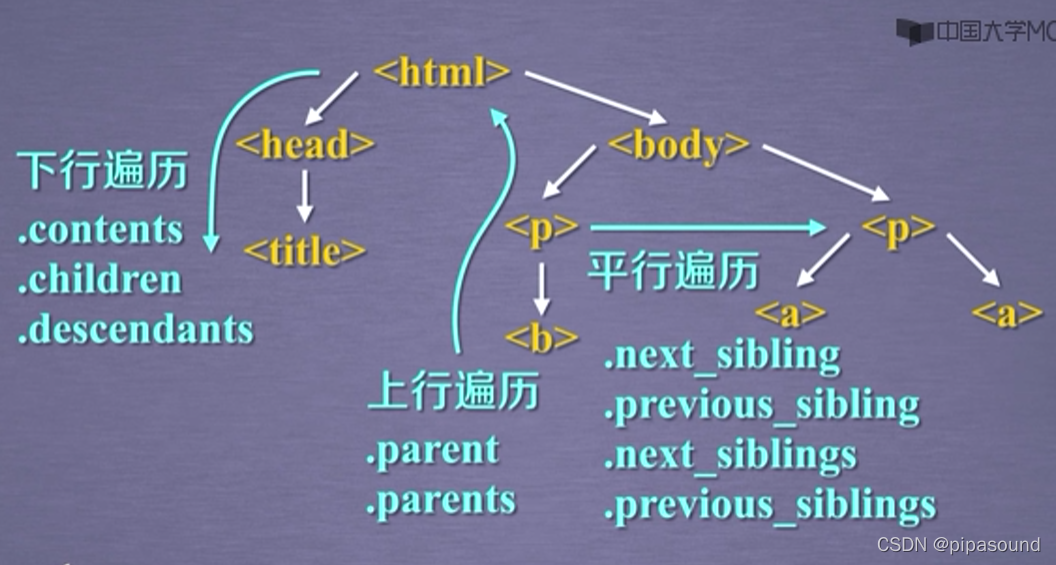
5,基于bs4库的HTML内容遍历方法
标签树的下行遍历
? 标签树的上行遍历?
标签树的平行遍历
总结
? 6,基于bs4库的HTML格式输出
一,Requests库练习
- raise_for_status():若在回传的代码是200的情况下,是不会产生例外,否则产生例外
- 每次爬取前检查能否访问
1,用百度 360 搜索关键字
- 百度关键词搜索 http://www.baidu.com/s?wd=keyword
- 360关键字搜索 http://www.so.com/s?q=keyword
import requests
kv={'wd':'Python'}
r=requests.get("http://www.baidu.com/s",params=kv)
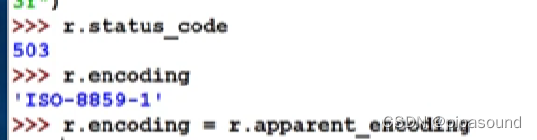
r.status_code
>>>200
r.request.url
>>>'http://www.baidu.com/s?wd=Python'
print(r.request.url)
>>>http://www.baidu.com/s?wd=Python
print(r.text[1000:2000])
当链接回传的非常多的时候,r.text可能会导致idle失效,所以尽量约束一个范围空间
2,图片爬取并保存本地
-
要考虑一切可能会发生的情况
import requests
import os
root = 'E://pictures//'
url = 'https://cj.jj20.com/2020/down.html?picurl=/up/allimg/tp03/1Z9211U233AA-0.jpg'
path = root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url=url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("该档案保存成功")
else:
print('档案已存在')
except:
print("爬取失败")二,网络爬虫之信息提取——Beautiful soup库学习
1,安装Beautiful soup
from bs4 import BeautifulSoup
soup=BeautifulSoup('<p>data<p>','html.parser')
4,beautiful的基本使用元素
 beatiful soup库 决议器
beatiful soup库 决议器

beautiful soup类基本元素

soup.head.contents
>>>[<title>This is a python demo page</title>]
soup.body.contents
>>>['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n']
len(soup.body.contents)
>>>5
soup.body.contents[1]
>>><p class="title"><b>The demo python introduces several python courses.</b></p>
//可用回圈进行遍历
for child in soup.body.children:
print(child)
 标签树的上行遍历
标签树的上行遍历
soup.a.next_sibling
>>>' and '
soup.a.next_sibling.next_sibling
>>><a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
- 遍历前续节点(回圈)
for sibling in soup.a.previous_siblings:
print(sibling)
总结
 6,基于bs4库的HTML格式输出
6,基于bs4库的HTML格式输出
- print(soup.prettify())
-
print(soup.a.prettify())
>>> <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
-
soup.a.prettify()
>>>'<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">\n Basic Python\n</a>\n'






0 评论